【超便利】python BeautifulSoupでスクレイピングする手順
pythonで出来ることで最も魅力的なことの一つとしてスクレイピングがあります。
スクレイピングとはウェブ上のデータをプログラムを通して取得するツールで、やり方をマスターすればその活用方法は無限大です。
Pythonでスクレイピングを行うツールとして、代表的なものにSeleniumとBeautifulSoupの二つがあります。Seleniumは実際にブラウザを起動して特定の操作(クリックやキー入力)を行いながら動的なサイトをスクレイピングできる一方で、BeautifulSoupは完全にバックグラウンドで行われ、実際にブラウザが起動するわけではないので、ブラウザをスクロールした後に描写される情報などを取得するのには適していません。ただし、軽量でSeleniumと比較した際に動作が早いので、静的なサイトから情報を取得したい際にはBeautifulSoupを使うといいでしょう。
今回はBeautifulSoupの使い方について解説します。Pythonの環境構築が済んでいる方であれば、pipでのインストールのみで手軽に利用できるのもメリットの一つです。
仮想環境を作成する
名前は何でもいいので、作業用ディレクトリを任意の場所に作成しましょう。
ターミナルで作業用ディレクトリを開いたら、仮想環境を作成します。今回はscrapeという名前の仮想環境を作成します。以下のコマンドを実行してください。
python -m venv scrapeすると同ディレクトリ内にscrapeというフォルダが作成され、仮想環境用のファイルが生成されるので、次のコマンドを入力して仮想環境を有効にします。
./scrape/Scripts/Activate.ps1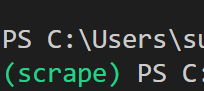
ここまで正常に行えていれば、仮想環境が有効になり、コマンドラインの冒頭に(scrape)と表示されているはずです。これで下準備は整いましたので、さっそくBeautifulSoupをインストールしていきます。
BeautifulSoupをインストールする
Seleniumはモジュールのインストールに加え、自動操作用のブラウザであるdriverというものを別途ダウンロードする必要がありますが、BeautifulSoupはモジュールのインストールのみで使用することができます。以下のコマンドを実行してBeatifulSoupをインストールしましょう。
pip install BeautifulSoup4 
これでBeautifulSoupが使えるようになりましたので、次はコードを書いていきます。
Yahooニュースの最新見出しを取得してみる
main.pyというファイルを作成してください。
以下のコードをコピぺしてください。
# main.py
from bs4 import BeautifulSoup
import requests
url = 'https://news.yahoo.co.jp/'
res = requests.get(url=url).content
soup = BeautifulSoup(res, 'html.parser')
elem = soup.find('section', attrs={'id': 'uamods-topics'})
elem = elem.find('div', attrs={'class': 'sc-tVThF dWDvEd'})
lis = elem.find_all('li')
for li in lis:
print(li.text)実行する前に、pythonからウェブにアクセスするためのrequestsモジュールもインストールしましょう。
pip install requestsこれで実行準備が整いましたので、コンソールからmain.pyを実行してみてください。

実行時のヤフーニュースと比べてみます。
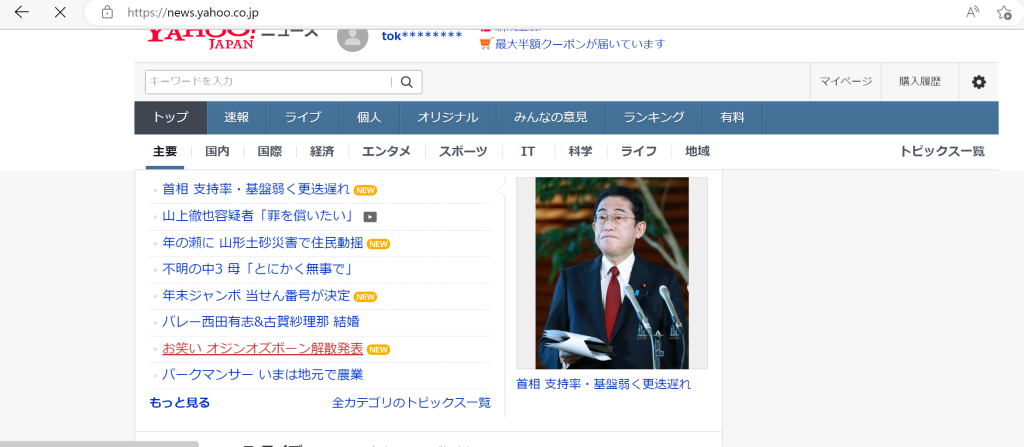
ちゃんとトップの見出しが抜き出せていることがわかります。
それではコードの解説を順番にしていきます。
from bs4 import BeautifulSoup
import requestsまずこの部分でインストールした‘BeautifulSoupとrequestsモジュールをインポートしてコード内で使えるようにしています。
BeautifulSoup4はbs4というモジュール名で扱われるので、その中からBeautifulSoupのみをインポートしています。
url = 'https://news.yahoo.co.jp/'
res = requests.get(url=url).content
soup = BeautifulSoup(res, 'html.parser')url変数にはヤフーニュースのURLを文字列として代入します。そのurl変数を使用して、requests.get()を用いて、指定したURLにアクセスし、帰ってきた結果をres変数に代入しています。
いよいよBeautifulSoupの出番です。res変数には.contentで取得したHTMLの内容がbytes型で入っているので、これを扱いやすくするためにhtml.parserを用いて、実際のHTMLファイルの内容に近い形に変換します。
ちなみにこの時点でのsoup変数の中身を出力すると以下のようになっています。
escription":"Yahoo!ニュースは、新聞・通信社が配信するニュースのほか、映像、雑誌や個人の書き手が執筆する記事など多種多様なニュースを掲載しています。","type":"website","yads":{"categoryId":"227"},"enableAppLink":true},"newsFeedTab":{"subCategories":[],"isReflectedStorage":false},"newsFeedLocalTab":{"regions":[]},"subTopics":{"title":"","url":"","list":[]},"notice":{"notices":[{"label":"コメントタイムライン","type":"announce","mediaTagId":null,"createTime":"2022-12-21T15:03:28+09:00","placements":[{"position":"right_top","webCategory":"major"},{"position":"right_top","webCategory":"domestic"},{"position":"right_top","webCategory":"world"},{"position":"right_top","webCategory":"business"},{"position":"right_top","webCategory":"entertainment"},{"position":"right_top","webCategory":"sports"},{"position":"right_top","webCategory":"it"},{"position":"right_top","webCategory":"science"},{"position":"right_top","webCategory":"life"},{"position":"right_top","webCategory":"local"}],"contents":[{"title":"最新コメントでみんなの話題をチェック","description":"コメントタイムラインでニュースを見よう","linkUrl":"https://news.yahoo.co.jp/comment-timeline","imageUrl":"https://s.yimg.jp/images/news-fe-ops/notice/img/temporary/comment_timeline_80x80.png"}]},{"label":"Yahoo!ニュース タイアップ","type":"announce","mediaTagId":null,"createTime":"2022-12-14T12:27:23+09:00","placements":[{"position":"right_bottom","webCategory":"local"}],"contents":[{"title":"地域のために何ができる? 各地で生きる人々の記事から読み解く","description":"提供:各種企業・団体","linkUrl":"https://news.yahoo.co.jp/sponsored/list/furusato/","imageUrl":"https://s.yimg.jp/images/news-fe-ops/notice/img/pr_102x102.png"}]}]},"pageError":{"textMain":"情報を取得できませんでした。","textSub":"システムエラーのため、情報を取得できませんでした。しばらくしてから再度お試しください。"},"horseRacing":{"isShow":false},"soccerJ1League":{"isShow":false},"soccerJLeagueCup":{"isShow":false},"soccerOverseas":{"isShow":false},"baseballNpb":{"isShow":false},"baseballMlb":{"isShow":false},"searchConditions":{"query":"","initialCategories":{"domestic":false,"world":false,"business":false,"entertainment":false,"sports":false,"it":false,"science":false,"life":false,"local":false},"latestCategories":{"domestic":false,"world":false,"business":false,"entertainment":false,"sports":false,"it":false,"science":false,"life":false,"local":false},"suggestList":[],"qrw":true},"userToken":"v8uvYwAAAACa8bg83tca0eCdojP1CCyckhToSvBhgXrJJViHrX9cFs-G8omntVWq8IPQGJQ3jKScxi7baeVulDngpBaWMwad"}</script><script src="https://s.yimg.jp/images/ds/cl/ds-custom-logger-1.1.0.min.js"></script><script src="https://s.yimg.jp/images/ds/yas/ual-2.11.0.min.js"></script><script>
window.ualcmds = window.ualcmds || [];
window.ual = window.ual || function() {
hierarchy_id: '2080283908',
mtestid:'mfn_18800=ttlg1t1'
});
</script><script src="https://s.yimg.jp/images/news-web/versions/20221220-4e2fffc54b/pc/js/top.js" type="text/javascript"></script></body></html>すべては載せきれなかったので、終わりから何行か抽出しています。
御覧の通り、HTMLタグが表示されており、アクセス先のHTMLファイルを取得していることがわかります。
ここからBeautifulSoupのメソッドを使って、必要な情報のみを抽出していくことになります。
主に使うのはfind()とfind_all()です。
elem = soup.find('section', attrs={'id': 'uamods-topics'})
elem = elem.find('div', attrs={'class': 'sc-tVThF dWDvEd'})
lis = elem.find_all('li')
for li in lis:
print(li.text)一行目ではsoup変数のfind()を用いてidがuamods-topicsのsectionタグを抽出しています。
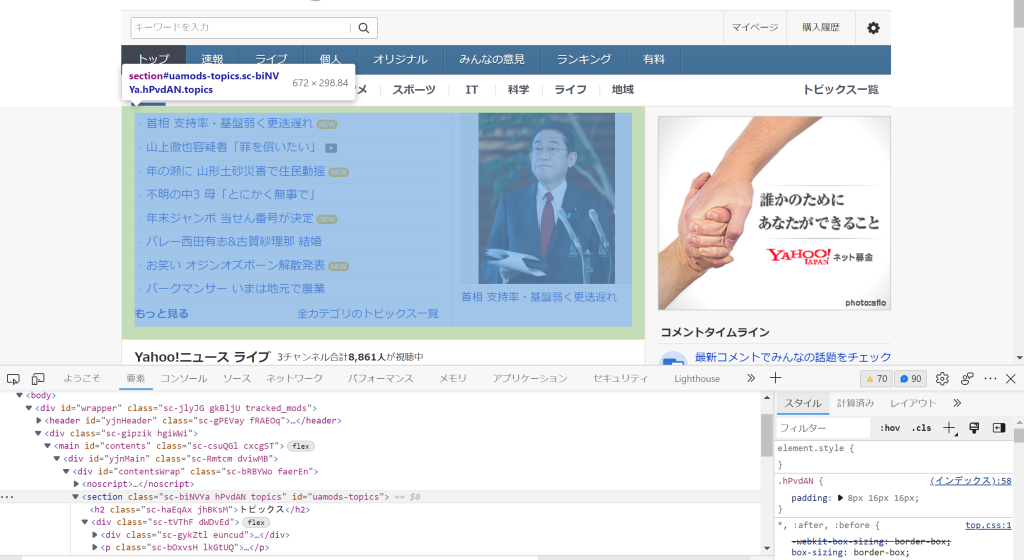
ブラウザ上でCtrl+Shift+Cを押すと開発者ツールが開き、カーソルを当ててる場所に対応するHTML上での要素が表示されます。
その要素を取得したいので、タグ名をfind()メソッドに指定しますが、それだけだとすべてのsectionタグの中から最初の一つを取得することになるので、追加の情報として今回はidを指定しています。idは基本的にはユニークなものなので、id属性が付与されているタグであればidを指定しておくのが確実です。
ここまででsectionタグの中身のみを抽出することができました。ほしい情報は見出し一覧ですので、さらに開発者ツールを使って深堀していくと、
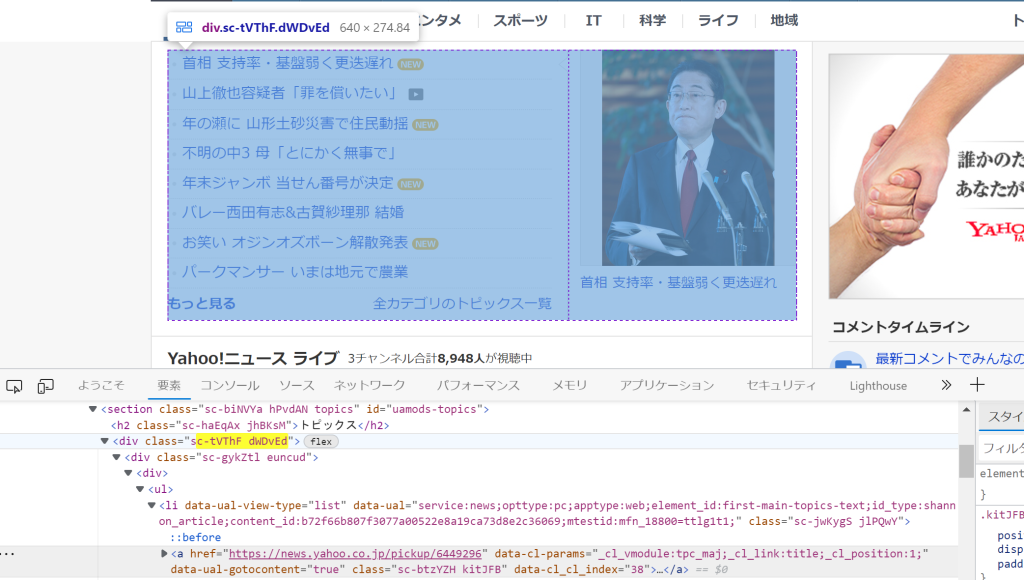
sc-tVThF dWDvEdというクラスをもつdivタグがあったので、そちらを取得していきます。
先ほども使っていましたが、find()メソッドの二つ目の引数にattrs={‘class’: ‘sc-tVThF dWDvEd’}でクラス名を指定しています。attrsには辞書型を渡します。キーに属性名、値に属性に対応する値を指定します。
idやclass以外でも属性であれば指定できるので、これだけでもかなり柔軟に要素を抽出することができます。
むやみに変数の数を増やしたくないので、elemという変数に上書きする形で深堀していきます。
最後にdiv要素の中にあるすべてのli要素を取得するために、find_all()を使っています。
find_all()メソッドにはタグ名のみを指定しています。
find_all()は条件に合致する要素をすべてを取得してくるので、div内の全てのliタグの中身を取得していますが、divを取得するまでに十分に絞れているので、liには必要な情報のみが含まれています。
この過程を飛ばして、最初からsoup.find_all(‘li’)などとやってしまうと、HTMLに含まれるすべてのliタグが取得されてしまうので、必要な情報の外枠から順番に指定していきましょう。今回私が指定した順番以外にももっと効率よくたどり着く方法もあると思いますので、慣れてきたらできるだけ無駄がなく、かつ必要な情報にアプローチできるように心がけましょう。
最後にfor文でliタグに含まれるテキストを出力しています。
まとめ
BeautifulSoupを使ったスクレイピング方法について解説しました。
初心者でも簡単にできる手法ですので、ぜひ活用してみてください。需要がありそうであればSeleniumを用いたスクレイピング方法についても今後解説しようかと思います。
なお、冒頭でも述べましたが、スクレイピングを行う際はルールとマナーを守って行いましょう。