【Python】Javascriptでレンダリングされるサイトをスクレイピングする方法
サイトのスクレイピングはBeautifulSoupやSeleniumといったライブラリを利用して行うことができますが、中には簡単にはスクレイピングできないようなサイトもあります。
例えばJavascriptで制御されているサイト、いわゆる動的なサイトはブラウザでサイトが開かれた後にJavascriptが実行され、そこではじめてHTMLが生成・描写されるためBeatifulSoupでは取得できません。React.jsやAngular.js、JQueryといったフレームワークを利用して作られたサイトなど、Javascriptで制御されているサイトは数多くあり、増加傾向にあります。
Seleniumでブラウザを開き、ゴリゴリにやっていくことも不可能ではありませんが、いまいち動作が安定しないのと、何かと不具合が多いのでこちらも簡単ではありません。
今回はBeautifulSoupよりもシンプルに、Seleniumよりも安定してJavascriptでレンダリングされるサイトをスクレイピングできるAPIを発見したので紹介したいと思います。
その名はScrapingBee
ScrapingBeeではJavascriptで制御されたページで何かしらの操作(クリックやスクロールなど)をした後しか表示されないような内容まで簡単にスクレイピングすることができます。以下ではScrapingBeeの使い方を解説していきます。
目次
APIキーを取得
まずはScrapingBeeを利用するためにAPIキーが必要ですので、公式サイトから取得します。
リンクをクリックすると上のような画面が表示されると思いますので、Try ScrapingBee for Freeをクリックしてください。
その後、メールアドレスまたはGoogleアカウントまたはGithubアカウントで登録するかを選べますので、お好きな方法で登録してください。
登録が完了したら以下のダッシュボード画面が表示されると思います。(されない場合はもう一度トップページがTry ScrapingBee for Freeをクリックするとダッシュボードに飛びます)
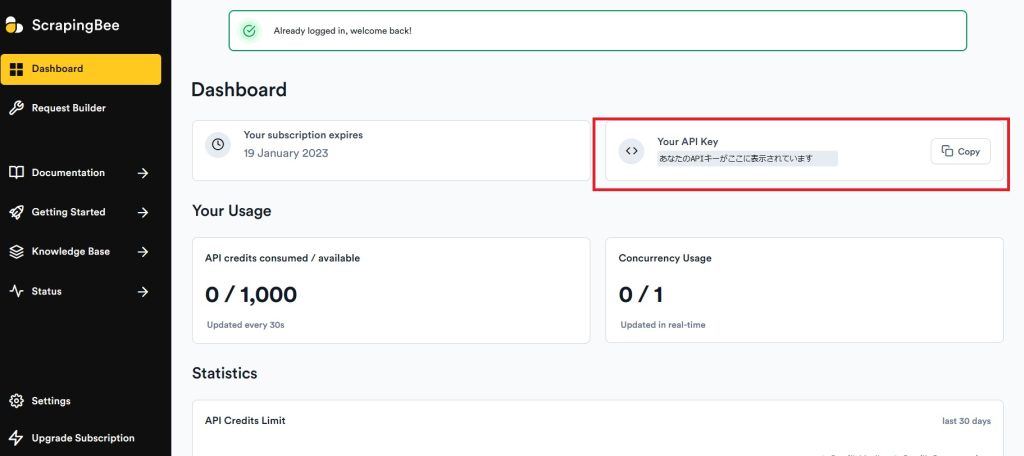
右上にYour API Keyセクションがあるので、CopyをクリックしてAPIキーを保存しておいてください。
Pythonコードを書く
ScrapingBeeライブラリを利用しますので、以下のコマンドでインストールします。
pip install scrapingbeefrom scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get("YOUR-URL")
print('Response HTTP Response Body: ', response.content)
Pythonコードは上記のたった4行です。
以下のような結果が返ってきます。
<html>
<head>
...
</head>
<body>
<content>
</content>
<content>
</content>
<content>
</content>
<content>
</content>
<content>
</content>
</body>
</html> ScrapingBeeClientオブジェクトを自分のAPIキーで作成したらgetメソッドにスクレイピングしたいサイトのURLを渡すだけです。getメソッドにparamsに辞書型のパラメーターを渡すことで様々な動作を指定することができます。下のrender_jsというパラメーターはデフォルトではTrueになっており、これによりJavascriptで描写されるサイトでもスクレイピングできるようになっています。
response = client.get('YOUR-URL',
params = {
'render_js': 'False',
}
)render_jsをFalseにした場合の結果は以下のようになります。
<html>
<head>
..
</head>
<body>
</body>
</html> Javascriptが描写されない状態で取得しているので、bodyタグの中身が空になってしまっています。
クリックやスクロールをさせてスクレイピングする
ScrapingBeeAPIはスクレイピングしたいサイトに対して何かしらのアクションをさせなければいけない場合でもパラメーターにjs_scenarioを渡すことによって実際のブラウザを操作しているかのような挙動を実現できます。
たとえばページ内のあるボタンをクリックしないと表示されないデータがある場合、そのボタンをクリックさせなければいけません。その場合、以下のコードで実現できます。
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get('YOUR-URL',
params = {
'js_scenario': '{"instructions": [{"click": "#buttonId"}]}',
}
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.content)
js_scenario’: ‘{“instructions”: [{“click”: “#buttonId”}]}の#buttonId部分にクリックしたいボタンのIDを指定するだけです。
便利なものとして以下のようなものがあります。他にもありますので、もっと知りたい方は公式ドキュメントを参考にしてください。
{"click": "#button_id"} # 要素をクリックさせる
{"wait": 1000} # 指定した時間(ミリ秒)待機
{"wait_for": "#slow_div"} # CSSで指定された要素が描写されるまで待機
{"wait_for_and_click": "#slow_div"} # CSSで指定された要素が描写されるまで待機し、その後要素をクリック
{"scroll_x": 1000} # 指定したpx分水平方向にスクロール
{"scroll_y": 1000} # 指定したpx分垂直方向にスクロール
{"fill": ["#input_1", "value_1"]} # input_1のIDを持つ要素に"value_1"を入力
{"evaluate": "console.log('toto')" # 指定したJavascriptコードを実行javascriptで描写されるサイトの中には要素が描写されるまで時間がかかるものもあり、描写が終わる前にスクレイピングしてしまうと中身が取得できていないことも多々あります。秒数指定でもいいのですが、描写までどれくらいかかるかわからないので安定しませんし、だからといって長く待ちすぎるのも嫌なので、wait_forはかなり便利です。秒数指定ではなく要素指定なので、その要素が描写されてから確実にスクレイピングしてくれます。
その他にも便利な機能がたくさんあるので、スクレイピングを極めたいならScrapingBeeは利用しない手はないでしょう。
具体的なユースケース #10月16日追記
ScrapingBeeのより具体的なユースケースやメリットを紹介してほしいという声を多くいただきましたので、紹介させていただきます。以下ではPythonでスクレイピングする場合を想定してサンプルコードの解説をしていきます。
①一般的なウェブスクレイピング
ScrapingBeeのAPIはECサイトの価格を監視する際や不動産・物件情報のスクレイピングなど、一般的なスクレイピングタスクをこなすのにも最適です。スクレイピングが難しいようなサイトでもブロックされずに情報を取得することができます。
②データ抽出
実際に私がScrapingBeeを使う場面で最も多いのがこのデータ抽出です。ScraipingBeeのAPIはデータ抽出をするのに非常に適していて、かなりカンタンに特定のサイトの必要な情報を抽出することができます。なんといっても強力なのが自動HTMLパース機能で、めんどうな整形処理を行わずにJson形式などでデータを抽出することができます。
例えばScraipingBee公式ブログのタイトル・サブタイトル・記事一覧を取得したい場合は次のようなコードで簡潔に記すことができます。
# pip install scrapingbee
from scrapingbee import ScrapingBeeClient
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get(
'https://www.scrapingbee.com/blog',
params={
'extract_rules':{
"title" : "h1",
"subtitle" : "#subtitle",
"articles": {
"selector": ".card",
"type": "list",
"output": {
"title": ".post-title",
"link": ".post-title@href",
"description": ".post-description"
}
}
},
},
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.json())
# ----------結果--------------
Response HTTP Status Code: 200
{
"title": "The ScrapingBee Blog",
"subtitle": " We help you get better at web-scraping: detailed tutorial, case studies and writing by industry experts",
"articles": [
{
"title": " Block ressources with Puppeteer - (5min)",
"link": "https://www.scrapingbee.com/blog/block-requests-puppeteer/",
"description": "This article will show you how to intercept and block requests with Puppeteer using the request interception API and the puppeteer extra plugin."
},
...
{
"title": " Web Scraping vs Web Crawling: Ultimate Guide - (10min)",
"link": "https://www.scrapingbee.com/blog/scraping-vs-crawling/",
"description": "What is the difference between web scraping and web crawling? That's exactly what we will discover in this article, and the different tools you can use."
},
]
}
paramsの’extract_rules’に取得したいデータを辞書形式で指定します。サンプルコードではタイトルはシンプルにh1タグで指定、サブタイトルはidがsubtitleの要素を指定、複数ある記事はCSSセレクターと”type”:”list”で指定した後に”output”に記事のタイトル、リンク、詳細をそれぞれクラス名で指定して取得しています。@hrefとすることで、要素の指定した属性の値を取得することができます。
視覚的にもかなりわかりやすいコードだと思います。
スクリーンショットを撮りたい場合
スクレイピングするサイトのスクリーンショットを撮りたい場合などもあるかと思います。
ScrapingBeeのAPIを利用することで超簡単にスクリーンショットをとることもできちゃいます。
# pip install scrapingbee
client = ScrapingBeeClient(api_key='YOUR-API-KEY')
response = client.get(
'YOUR-URL',
params={
'screenshot': True,
}
)
if response.ok:
with open("./screenshot.png", "wb") as f:
f.write(response.content)
ScrapingBee APIでスクリーンショットを撮る方法はparamsに’screenshot’: Trueを渡してあげるだけです。スクリーンショットが格納されたresponseを上のサンプルコードのようにすることで画像を保存することができます。
スクリーンショットはrender_js=Trueになっている場合のみ撮ることができます。Javascriptでレンダリングされるサイトもレンダリング後にスクリーンショットを撮れるようにするためです。
またScrapingBeeにはスクレイピングを高速化するためのオプションの一つとしてblock_resourcesがありますが、これは画像などスクレイピングに必要ない情報のレンダリングを無視することで高速化をはかるものですが、screenshot=Trueにした場合は当然ですがこちらのオプションは自動的にFalseになります。
Googleの検索結果のスクレイピング
様々な理由でGoogleの検索結果の内容をスクレイピングしたい方は多いと思います。実際にエンジニアとして働いていると、検索結果の内容をスクレイピングしてほしいという依頼をよくいただきます。
が、Googleの検索結果のスクレイピングは非常に難しく、通常のアプローチではすぐにロボット判定されてブロックされてしまいます。
ScrapingBeeではGoogle Search APIというまさにGoogle検索結果を取得するため専用のAPIが用意されているので、高度な技術を必要とせずに簡単に検索結果を取得できてしまいます。
オーガニック検索結果や広告情報、ローカル情報、Google Mapの情報、関連したクエリなど、さまざまな情報の取得に対応しているので、非常に使い勝手がいいかと思います。
# `pip install requests`
import requests
def send_request():
response = requests.get(
url="https://app.scrapingbee.com/api/v1/store/google",
params={
"api_key": "YOUR-API-KEY",
"search": "pizza new-york",
},
)
print('Response HTTP Status Code: ', response.status_code)
print('Response HTTP Response Body: ', response.content)
send_request()
コードは上記のようにかなりシンプル。
paramsに自分のAPIキーと検索したいワードを渡すだけです。
「pizza new-york」で検索した場合の結果は以下のようになります。
{
"bottom_ads": [],
"knowledge_graph": {},
"local_results": [
{
"position": 1,
"review": 4.6,
"review_count": 62,
"title": "NY Pizza Suprema"
},
...
],
"meta_data": {
"location": null,
"number_of_ads": 0,
"number_of_organic_results": 20,
"number_of_page": 363000000,
"number_of_results": 363000000,
"url": "https://www.google.com/search?q=pizza+new+york&hl=en&num=20"
},
"organic_results": [
{
"date": null,
"date_utc": null,
"description": null,
"displayed_url": "https://www.tripadvisor.com › ... › New York City",
"domain": "www.tripadvisor.com",
"position": 1,
"rich_snippet": {},
"sitelinks": [],
"title": "THE 10 BEST Pizza Places in New York City (Updated 2023)",
"url": "https://www.tripadvisor.com/Restaurants-g60763-c31-New_York_City_New_York.html"
},
{
"date": null,
"date_utc": null,
"description": "New York–style pizza is pizza made with a characteristically large hand-tossed thin crust, often sold in wide slices to go. The crust is thick and crisp ...",
"displayed_url": "https://en.wikipedia.org › wiki › New_York–style_pizza",
"domain": "en.wikipedia.org",
"position": 2,
"rich_snippet": {
"top": {
"attributes": [
{
"name": "Main ingredients",
"value": "Pizza dough, tomato sauce, ..."
},
{
"name": "Region or state",
"value": "New York City, New York"
}
],
"attributes_flat": "Main ingredients: Pizza dough, tomato sauce, ..., Region or state: New York City, New York",
"detected_extensions": {}
}
},
"sitelinks": [],
"title": "New York–style pizza",
"url": "https://en.wikipedia.org/wiki/New_York%E2%80%93style_pizza"
},
...
],
"questions": [
{
"answer": "New York-style pizza has slices that are large and wide with a thin crust that is foldable yet crispy. It is traditionally topped with tomato sauce and mozzarella cheese, with any extra toppings placed on top of the cheese. Pizza without additional toppings is called “plain,” “regular,” or “cheese.”",
"position": null,
"text": "What pizza is New York famous for?"
},
...
],
"related_queries": [
{
"position": 0,
"title": "best pizza in new york manhattan",
"url": "https://www.google.com/search?num=20&hl=en&q=Best+pizza+in+New+York+Manhattan&sa=X&ved=2ahUKEwjctLPoq4uAAxWUmWoFHRs4DmgQ1QJ6BAgxEAE"
},
...
],
"related_searches": [
{
"link": "https://www.google.com/search?num=20&hl=en&q=Best+pizza+in+New+York+Manhattan&sa=X&ved=2ahUKEwjctLPoq4uAAxWUmWoFHRs4DmgQ1QJ6BAgxEAE",
"position": 0,
"query": "best pizza in new york manhattan",
"type": "standard"
},
...
],
"top_ads": [
{
"description": "Cheap UK Pizza: Compare pizza in the UK",
"domain": "uk-go-pizza.com",
"position": 1,
"sitelinks": [],
"snippet": null,
"title": "Compare UK Pizza - Pizza - UK Pizza",
"tracking_url": "https://www.google.com/aclk?sa=l&ai=DChcSEwjU1qrRrYuAAxUVn1oFHdLZBI8YABAAGgJ2dQ&ae=2&sig=AOD64_3CFgH0bQFdqiC1kwZfEpVChxRd4g&q&adurl",
"url": "https://uk-go.com/home-insurance/",
"visual_url": "uk-go.com"
}
],
"bottom_ads": [
{
"description": "Cheap UK Pizza: Compare pizza in the UK",
"domain": "uk-go-pizza.com",
"position": 1,
"sitelinks": [],
"snippet": null,
"title": "Compare UK Pizza - Pizza - UK Pizza",
"tracking_url": "https://www.google.com/aclk?sa=l&ai=DChcSEwjU1qrRrYuAAxUVn1oFHdLZBI8YABAAGgJ2dQ&ae=2&sig=AOD64_3CFgH0bQFdqiC1kwZfEpVChxRd4g&q&adurl",
"url": "https://uk-go.com/home-insurance/",
"visual_url": "uk-go.com"
}
],
"top_stories": [
{
"date": "2023-07-12T13:25:12.298Z",
"link": "https://www.grubstreet.com/2023/07/the-best-of-the-year-i-ate-ny-so-far.html",
"position": 2,
"source": "Grub Street",
"title": "The Best of NYC Eating in 2023 (So Far)"
}
],
"news_results": [
{
"date": "2023-07-11T09:23:18.283Z",
"domain": "www.cnbc.com",
"link": "https://www.cnbc.com/2023/07/10/pizza-delivery-driver-why-tipping-is-crucial.html",
"position": 1,
"snippet": "No week of pay is the same for pizza delivery driver Brendan Madden of Lincroft, New Jersey, because \"not everyone tips fairly.\"",
"source": "CNBC",
"title": "Tipping is 'not a sustainable system,' says 25-year-old pizza delivery driver: My income 'relies on the goodwill of others'"
}
],
"map_results": [
{
"address": "New York, NY",
"category": "pizza",
"link": "https://www.google.com/aclk?sa=l&ai=DChcSEwiH9968tNmBAxWrNa0GHQPvDw4YABAAGgJwdg&gclid=EAIaIQobChMIh_fevLTZgQMVqzWtBh0D7w8OEBAYAiAAEgJekvD_BwE&sig=AOD64_32J9Tmh5PKoq6WWVAXNhjXb9jvqA&q=&ctype=99&ved=2ahUKEwjgzNe8tNmBAxVxHDQIHUznDkAQhKwBegQIGxAZ&adurl=",
"phone": "(212) 831-0300",
"position": 2,
"price": "$",
"rating": "4.7",
"reviews": 2301,
"title": "Domino's Pizza"
}
]
}map_resultsにはGoogle Mapに表示される情報なども格納されています。