初心者でもわかる!PythonxSeleniumでWebスクレイピングする方法
今回はPythonとSeleniumを利用してWebスクレイピングする方法を初心者の方にもわかるように1から徹底解説していきます。
Seleniumはブラウザを自動操作させて、スクレイピングできるツールです。スクレイピングしなくても単純にブラウザの自動化として活用することもできます。
使いこなせれば非常に強力なツールなので、ぜひ最後まで読んでマスターしてください!
なおBeautifulSoupを用いたスクレイピングについては以前別の記事で紹介しているので、そちらを参考にしてください。
仮想環境を作成する
名前は何でもいいので、作業用ディレクトリを任意の場所に作成しましょう。
ターミナルで作業用ディレクトリを開いたら、仮想環境を作成します。今回はscrapeという名前の仮想環境を作成します。以下のコマンドを実行してください。
python -m venv scrapeすると同ディレクトリ内にscrapeというフォルダが作成され、仮想環境用のファイルが生成されるので、次のコマンドを入力して仮想環境を有効にします。
./scrape/Scripts/Activate.ps1
ここまで正常に行えていれば、仮想環境が有効になり、コマンドラインの冒頭に(scrape)と表示されているはずです。これで下準備は整いましたので、さっそくSeleniumをインストールしていきます。
Seleniumをインストールする
Seleniumを使用するためにはSeleniumモジュールのインストールとブラウザを自動化するためのDriverというソフトが必要になります。まずはpipでモジュールをインストールしましょう。Dr
コマンドラインにて以下のコマンドを実行してください。
pip install seleniumDriverをダウンロードする
次にブラウザを自動操作するためのDriverをダウンロードします。
通常のブラウザと同じようにDriverにもChrome、Firefox、Edgeといった種類があります。普段自分が使っているブラウザと同じものを選ぶといいでしょう。通常のChromeがインストールされていないのにChrome用のDriverをダウンロードしても動作しませんので、注意してください。
以下にそれぞれのDriverをダウンロードできるリンクをまとめておきますので、ご自身の環境にあったものをダウンロードしてください。
今回はChrome Driverを例に進めていきます。
Driverにはいくつもバージョンがあります。バージョンは通常のブラウザのバージョンに対応しているため、まずは自身のブラウザのバージョンを確認する必要があります。
Chromeの場合は設定→Chromeについての順でクリックするとバージョンを確認することができます。
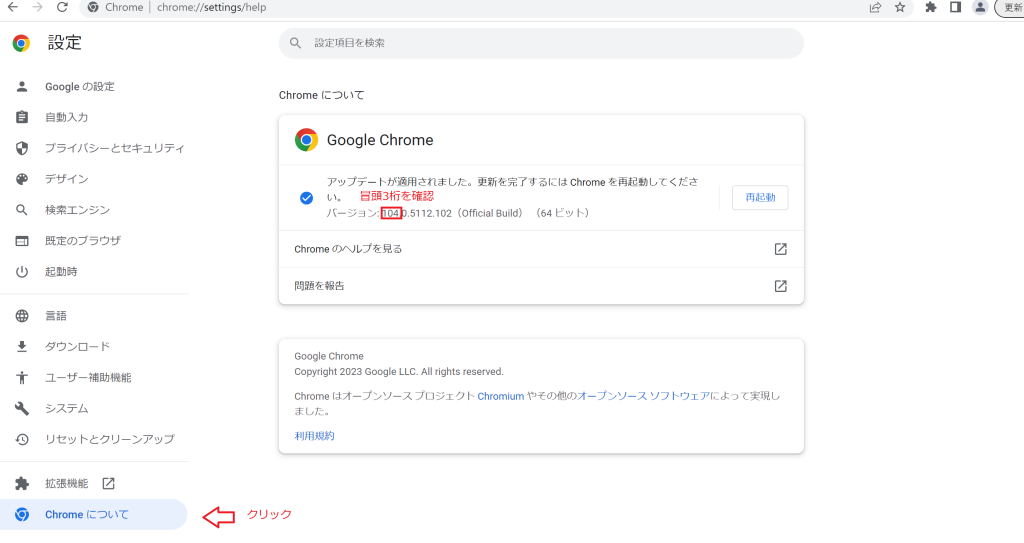
確認すべきはバージョン番号の上3桁ですので、ここでは104となります。
確認できたら先ほど載せたChrome DriverのダウンロードURLを開いてください。下の方にスクロールしていくと104に対応したバージョンのDriverが表示されます。
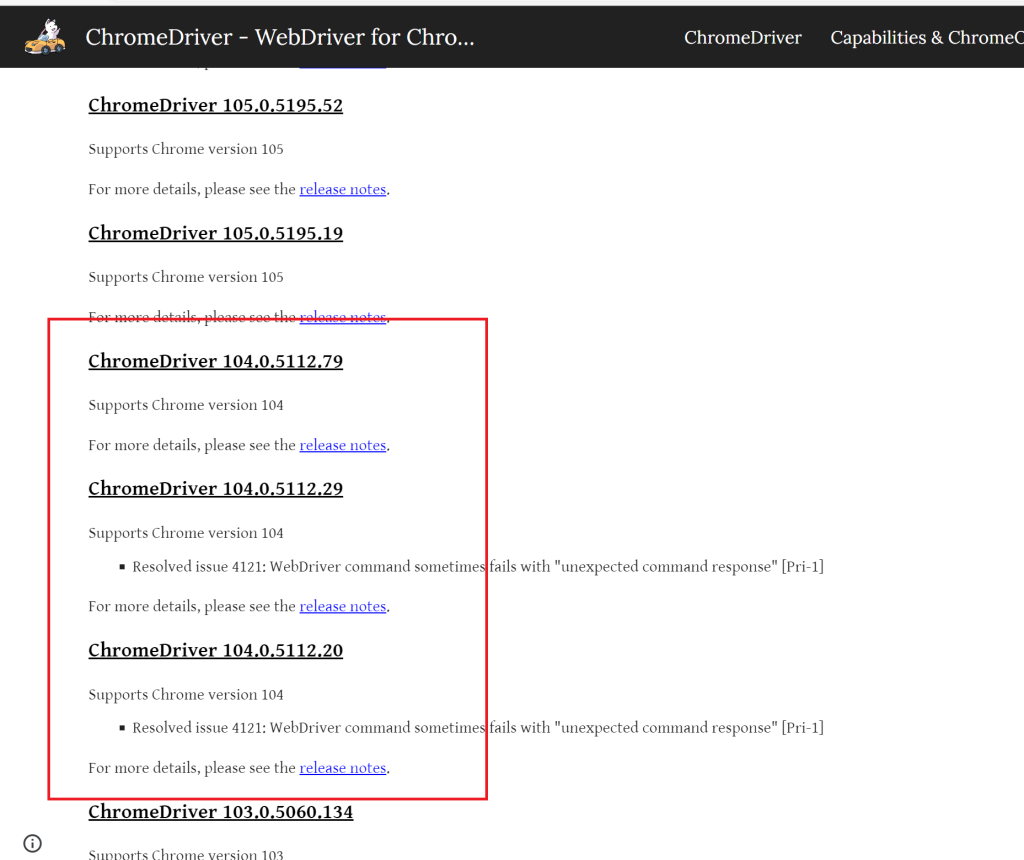
上3桁が一致したものであれば、どれでも構いませんので、一つ選んでクリックしてください。よくわからなかったら最新のものを選んでおけばいいかと思います。
リンク先にいくと以下のような画面が表示されますので、ご自身の環境にあったものをダウンロードしてください。
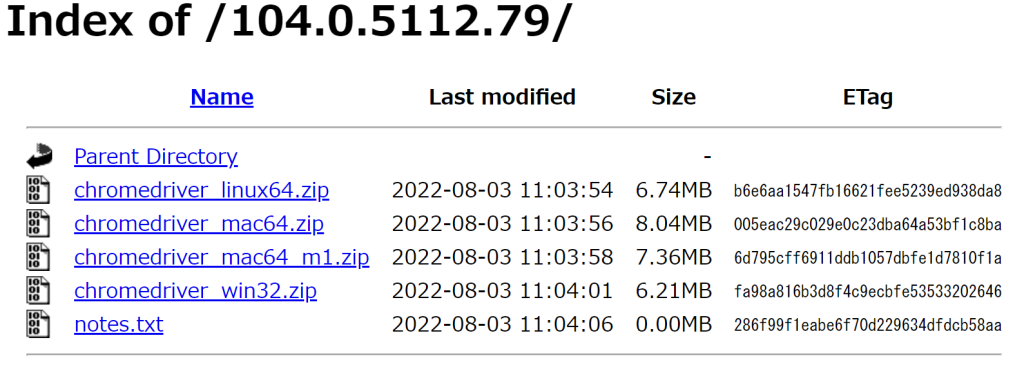
私はWindowsを使っているので、chromedriver Win32.zipをダウンロードします。
ダウンロードが完了したらファイルを解凍し、でてきたファイル(Windowsの場合はchromedriver.exe)を作業用ディレクトリのルート(一番上の階層)にコピーしてください。
これで下準備は完了です。
Yahooニュースをスクレイピングする
作業用ディレクトリにmain.pyというファイルを作成してください。
以下のコードをコピペしてください。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome(executable_path='./chromedriver.exe')
driver.get("https://news.yahoo.co.jp/")
elem = driver.find_element(By.CLASS_NAME, "sc-gykZtl.euncud")
lis = elem.find_elements(By.TAG_NAME, "li")
for li in lis:
print(li.text)
driver.quit()main.pyを実行してみましょう。
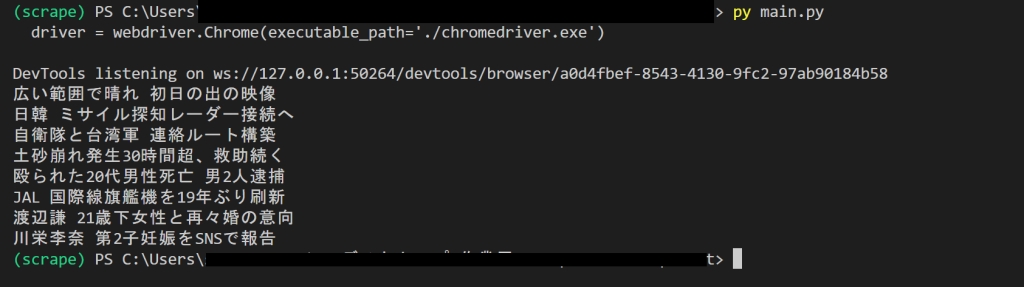
ブラウザが起動し、コンソールにYahooニュースの見出しが表示されましたね。
それではコードの解説を行います。
driver = webdriver.Chrome(executable_path='./chromedriver.exe')この一行で今回操作するブラウザのオブジェクトを作成しています。引数でダウンロードしたdriverのパスを指定しています。
driver.get("https://news.yahoo.co.jp/")
elem = driver.find_element(By.CLASS_NAME, "sc-gykZtl.euncud")
lis = elem.find_elements(By.TAG_NAME, "li")ブラウザでgetメソッドを使って引数に渡したURLを開いています。
find_elementメソッドを使って特定の要素を取得していますが、二行目ではクラス名で指定しています。
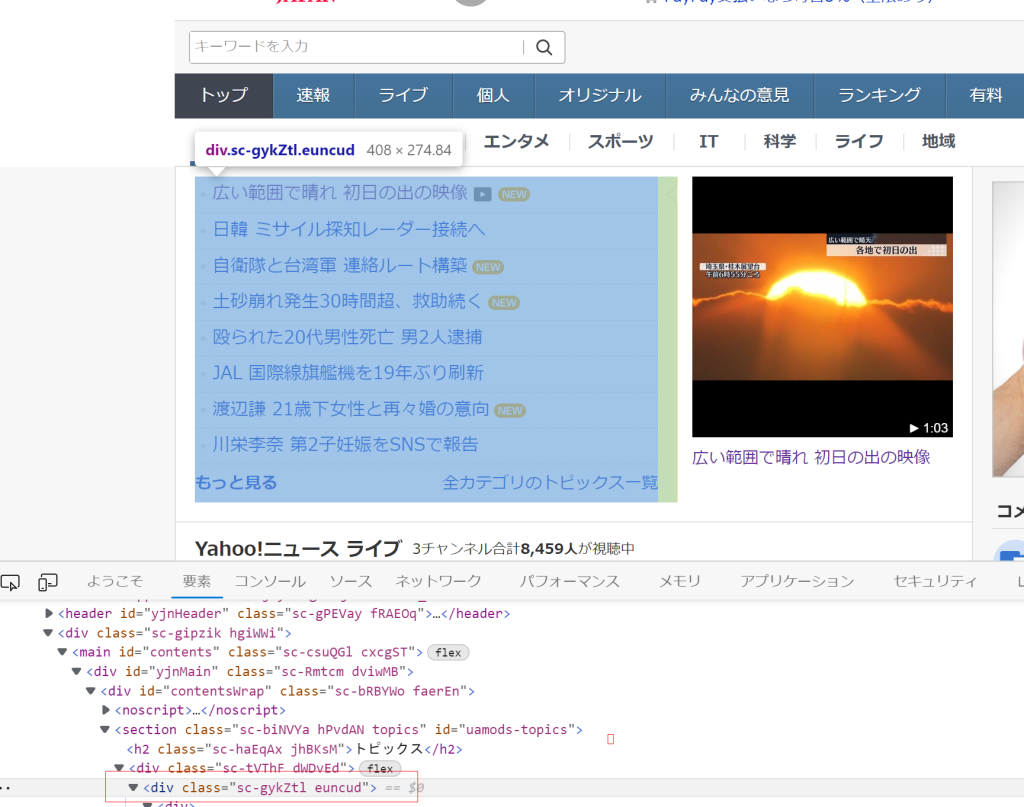
どうやって取得したい要素を指定するかについてですが、通常のブラウザでYahooニュースを開き、Ctrl+Shift+Cを押して、開発者ツールを開くとカーソルを当てた場所が青く表示され、それに対応するHTML上の要素が表示されます。
今回は見出し内容を取得したいので、見出し部分にカーソルをあてると、
<div class=”sc-gykztl euncud”>という要素が対応していることがわかりました。
<div>タグはHTML内にたくさんあるので、タグ名で指定することは難しいため、今回はほかの要素とかぶりのなかったクラス名を指定してあげています。クラス名で指定するには
第一引数にBy.CLASS_NAMEを渡し、第二引数にクラス名の文字列を渡します。クラス名が複数ある場合には、.(ドット)で結合します。クラス名以外にもタグ名やID属性、name属性などで指定することもできます。
もし同じタグが使われていない場合はタグ名で直接指定するのもOKです。
ひとまずこれでクラスに”sc-gykztl euncud”を持つdivタグを取得できましたので、次はその中の<li>タグをすべて取得しています。
注意点として、find_element()は一つの要素しか返さないのに対して、find_elements()は一致するすべての要素を返します。
今回はすべての見出し内容を取得したかったので、find_elements()にTAG_NAMEで”li”を指定することによって、div内の全てのliタグを取得しています。
取得したliタグはリストのようになっているので、for文でまわしてliタグに含まれるテキストを出力しています。
まとめ
いかがでしたか?今回はpythonとseleniumを用いてスクレイピングする方法を解説しました。
Seleniumはブラウザの自動操作をしながらスクレイピングが行える強力なツールですので、ぜひ使い方をマスターして活用してみてください。
Pythonでのスクレイピングを学ぶには以下の書籍が参考になりました。